Скачать с ютуб NLP: Understanding the N-gram language models в хорошем качестве
NLP: Understanding the N-gram language models
6 лет назад
Скачать бесплатно и смотреть ютуб-видео без блокировок NLP: Understanding the N-gram language models в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно NLP: Understanding the N-gram language models или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон NLP: Understanding the N-gram language models в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
NLP: Understanding the N-gram language models
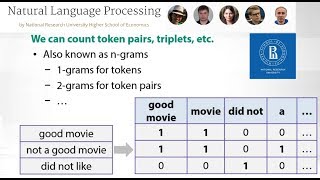
Hi, everyone. You are very welcome to week two of our NLP course. And this week is about very core NLP tasks. So we are going to speak about language models first, and then about some models that work with sequences of words, for example, part-of-speech tagging or named-entity recognition. All those tasks are building blocks for NLP applications. And they're very, very useful. So first thing's first. Let's start with language models. Imagine you see some beginning of a sentence, like This is the. How would you continue it? Probably, as a human,you know that This is how sounds nice, or This is did sounds not nice. You have some intuition. So how do you know this? Well, you have written books. You have seen some texts. So that's obvious for you. Can I build similar intuition for computers? Well, we can try. So we can try to estimate probabilities of the next words, given the previous words. But to do this, first of all,we need some data. So let us get some toy corpus. This is a nice toy corpus about the house that Jack built. And let us try to use it to estimate the probability of house, given This is the. So there are four interesting fragments here. And only one of them is exactly what we need. This is the house. So it means that the probability will be one 1 of 4. By c here, I denote the count. So this the count of This is the house,or any other pieces of text. And these pieces of text are n-grams. n-gram is a sequence of n words. So we can speak about 4-grams here. We can also speak about unigrams, bigrams, trigrams, etc. And we can try to choose the best n,and we will speak about it later. But for now, what about bigrams? Can you imagine what happens for bigrams, for example, how to estimate probability of Jack,given built? Okay, so we can count all different bigrams here, like that Jack, that lay, etc., and say that only four of them are that Jack. It means that the probability should be 4 divided by 10. So what's next? We can count some probabilities. We can estimate them from data. Well, why do we need this? How can we use this? Actually, we need this everywhere. So to begin with,let's discuss this Smart Reply technology. This is a technology by Google. You can get some email, and it tries to suggest some automatic reply. So for example, it can suggest that you should say thank you. How does this happen? Well, this is some text generation, right? This is some language model. And we will speak about this later,in many, many details, during week four. So also, there are some other applications, like machine translation or speech recognition. In all of these applications, you try to generate some text from some other data. It means that you want to evaluate probabilities of text, probabilities of long sequences. Like here, can we evaluate the probability of This is the house, or the probability of a long,long sequence of 100 words? Well, it can be complicated because maybe the whole sequence never occurs in the data. So we can count something, but we need somehow to deal with small pieces of this sequence, right? So let's do some math to understand how to deal with small pieces of this sequence. So here, this is our sequence of keywords. And we would like to estimate this probability. And we can apply chain rule,which means that we take the probability of the first word, and then condition the next word on this word, and so on. So that's already better. But what about this last term here? It's still kind of complicated because the prefix, the condition, there is too long. So can we get rid of it? Yes, we can. So actually, Markov assumption says you shouldn't care about all the history. You should just forget it. You should just take the last n terms and condition on them, or to be correct, last n-1 terms. So this is where they introduce assumption, because not everything in the text is connected. And this is definitely very helpful for us because now we have some chance to estimate these probabilities. So here, what happens for n = 2, for bigram model? You can recognize that we already know how to estimate all those small probabilities in the right-hand side,which means we can solve our task. So for a toy corpus again,we can estimate the probabilities. And that's what we get. Is it clear for now? I hope it is. But I want you to think about if everything is nice here. Are we done?
Comments