Скачать с ютуб SIMD and vectorization using AVX intrinsic functions (Tutorial) в хорошем качестве
SIMD and vectorization using AVX intrinsic functions (Tutorial)
2 года назад
Скачать бесплатно и смотреть ютуб-видео без блокировок SIMD and vectorization using AVX intrinsic functions (Tutorial) в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно SIMD and vectorization using AVX intrinsic functions (Tutorial) или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон SIMD and vectorization using AVX intrinsic functions (Tutorial) в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
SIMD and vectorization using AVX intrinsic functions (Tutorial)
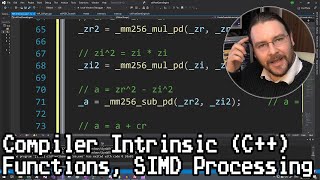
The best parallel programming technique you're probably not using. Using intrinsic functions to force SIMD parallelism per CPU core and gain speedups of between x4 and x16 on top of any other gains from threading etc. https://www.intel.com/content/www/us/... Gives examples of how to use the intrinsic functions to accelerate your numerical coding. Introductory Material (skip if you know what SIMD and intrinsics are) 00:00 Introduction 03:37 Intro to SIMD 05:17 SIMD instruction sets on x86 10:58 What are compiler intrinsics? 12:58 Simple comparison of standard C vs. AVX intrinsic summation Basic setup of AVX for use in C/C++ 15:11 Header files 16:25 Vector datatypes 18:19 Allocating memory 21:02 Intrinsic function naming 'convention' 23:55 Summary of AVX intrinsic functionality Examples of AVX intrinsics 27:28 Intro 27:45 Arithmetic (e.g. addition, subtraction, multiplication, division) [_mm256_add_ps, _mm256_mul_ps, _mm256_div_ps] 30:53 Fused-multiply add [_mm256_fmadd_ps] 33:52 Math functions (e.g. max,min,sqrt) [_mm256_max_ps, _mm256_sqrt_ps, _mm256_rsqrt_ps] 34:33 Logical (e.g. and, or, xor) [_mm256_and_ps] 35:06 Load/store [_mm256_load_ps, _mm256_loadu_ps] 36:18 Comparisons (e.g. greater than, equals, less than) [_mm256_cmp_ps] 39:05 Branchless programming (approximating an 'if' statement in SIMD) 41:57 Permute/shuffle (rearranging elements within a vector) [_mm256_permutevar8x32_ps, _mm256_permute4x64_pd, _mm256_permute_ps] 46:20 What's a 'lane'? 49:10 Insert/extract [_mm256_insertf128_ps, _mm256_extractf128_ps] 49:51 Blend [_mm256_blend_ps] 50:30 Gather/scatter [_mm256_i32gather_ps] 52:22 Horizontal add [_mm256_hadd_ps] 53:12 Conversion (e.g. float32 to int32) [_mm256_cvtepi32_ps, _mm256_cvtps_epi32, _mm256_cvtps_pd, _mm256_cvtepi32_epi64] 53:34 Set (pseudo-intrinsic) [_mm256_set_ps, _mm256_set1_ps] Programming example 54:45 Complex dot product 63:14 Vector reduction
Comments