Скачать с ютуб "Apache Kafka and the Next 700 Stream Processing Systems" by Jay Kreps в хорошем качестве
"Apache Kafka and the Next 700 Stream Processing Systems" by Jay Kreps
9 лет назад
Скачать бесплатно и смотреть ютуб-видео без блокировок "Apache Kafka and the Next 700 Stream Processing Systems" by Jay Kreps в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно "Apache Kafka and the Next 700 Stream Processing Systems" by Jay Kreps или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон "Apache Kafka and the Next 700 Stream Processing Systems" by Jay Kreps в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
"Apache Kafka and the Next 700 Stream Processing Systems" by Jay Kreps
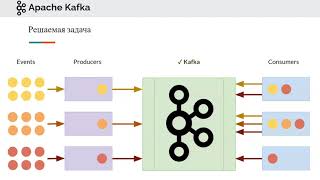
Most software systems continuously transform streams of inputs into streams of outputs. Yet the idea of directly modeling stream processing in infrastructure systems is just coming into it's own after a few decades on the periphery. This talk will cover the basic challenges of reliable, distributed, stateful stream processing. It will cover how Apache Kafka was designed to support capturing and processing distributed data streams by building up the basic primitives needed for a stream processing system. Finally it will explore how these kind of infrastructure maps to practical problems based on our experience building and scaling Kafka to handle streams that captured hundreds of billions of records per day. Jay Kreps CONFLUENT @jaykreps Jay Kreps is the CEO of Confluent, Inc. He was formerly the lead architect for data infrastructure at LinkedIn. He is among the original authors of several open source projects including Project Voldemort, a key-value store, Apache Kafka, a distributed messaging system, and Apache Samza a stream processing system.
Comments